Intro concepts
Evals and the data flywheel are what will make or break AI products
Evals are the base infrastructure to do future work on prompt engineering, few-shot learning, RAG, and fine-tuning.
We make systems better by looking at A LOT of data. The point of evals is to make us look at the right places so we can make our agents better.
Through this process, we force ourselves to strictly define what are pass and fail conditions for each eval. Human experts should be included at every step of the process. They provide ground truth and craft what the criteria for the evals should be. Eval judges should converge to human experts.
There are many types of evals, but you should use judges
Judges are when we use LLMs themselves to perform the evals. This is in contrast to humans doing the evals, or traditional ML techniques that can be based on things like embedding similarity to references.
Judges let you move extremely fast, and allow scaling to performing evals on all AI activity, adding to the flywheel.
Judges are not a perfect solution, they have downsides around bias, not capturing complexity, and not having measurable uncertainty. LLMs eating their own tails (aka LLMception) are discussed in Who Validates the Validators?. We should consider other types of evals down the line.
Here is a critical discussion of the approach. Upsides, downsides, theoretical and evidence-based evaluations. Critical Analysis of the ‘LLM-as-a-Judge’ Approach
Classifier judges and Comparison judges
For subjective outcomes (tone, persuasiveness, conciseness), you will get better consistency and resolution with evals that compare which is better between two options rather than direct scoring. This is true for both humans and LLM evals. We can simulate a lot of data and use judges to do pairwise comparisons to create ELO scores or similar to determine which agents are better.
I am making an assumption that we care more about objective outcomes first, which is why I’m focusing on binary classification judges. But different use cases may require more thought on doing pairwise comparison judges first.
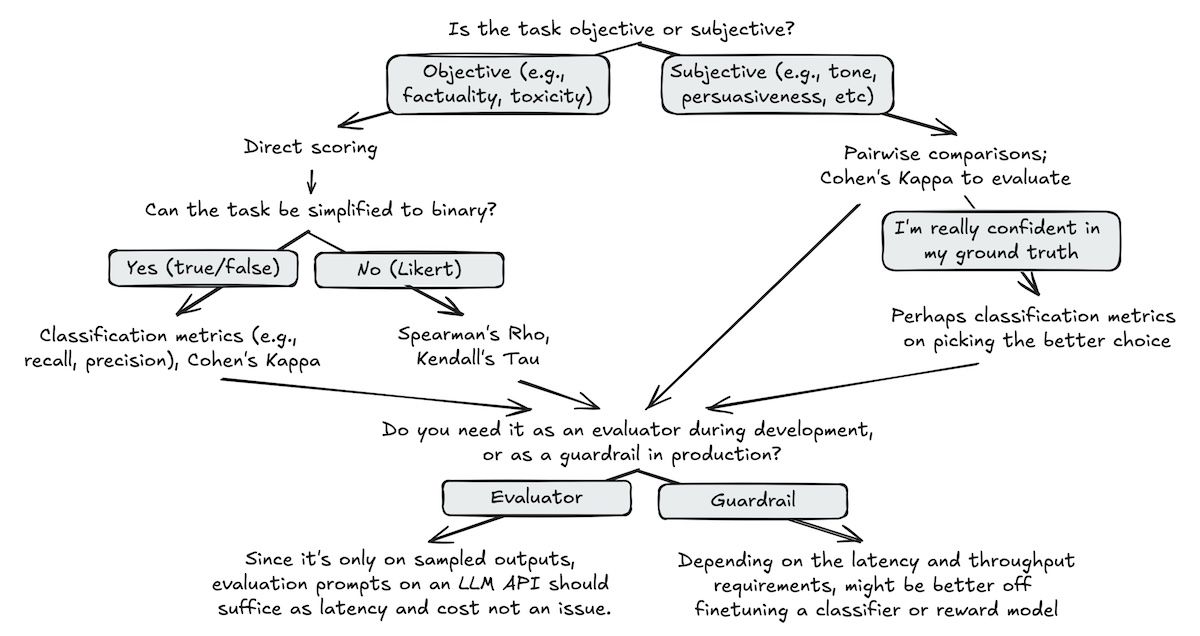
Building effective binary classification judges
Principles
- Human experts should be deeply integrated into every project
- Evaluation criteria have to be expanded and refined as you go
- Use binary evaluation wherever possible. Evals seem fairly useless without this, and it forces us to make actionable changes (rather than scoring or a 1-5 scale). Make binary judgments specific, and have more of them, rather than ambiguous catch-alls.
- Turn every problem into an eval/test
- Use the most powerful model we can afford. Eval logic is hard. (except for guardrails, which must be latency sensitive)
- Remove ALL friction from looking at data.
- Keep it simple. Don’t buy fancy LLM tools. Use what you have first.
- You are doing it wrong if you aren’t looking at lots of data.
- Don’t rely on generic evaluation frameworks to measure the quality of your AI. Instead, create an evaluation system specific to your problem.
- Write lots of tests and frequently update them.
- LLMs can be used to unblock the creation of an eval system. Examples include using an LLM to:
- Generate test cases and write assertions
- Generate synthetic data
- Critique and label data etc.
- Re-use your eval infrastructure for debugging and fine-tuning.
An order of how to go about it
1. Unit Evals
- Basic expected functionality should be made into discretized unit evals
- (calling functions, not returning UUIDs in response, etc.)
- Use LLMs to create synthetic conversations to run against these tests
- Set failure based on a certain % that don’t pass the tests. Not as simple as pass/fail on everything.
- Run and track tests regularly
2. Tracing
You must remove all friction from the process of looking at data
Maybe something like https://www.langchain.com/langsmith (does not require langchain)
Every agent should have custom tracing and a UI to view it:
- custom for each agent
- distinguishing between synthetic and real data
- filters to navigate examples
- Ability to tag examples as good/bad responses for each eval
3. Create a Synthetic dataset
-
It is absolutely fine and desirable to start with synthetic data before rolling things out
-
What you generally want is conversations between simulated users and your agents
-
We want high diversity. A framework we can use to generate the dataset is to use LLMs to generate conversations that are combinations of:
- Feature
- Scenario
- Persona
-
Consult with the expert to make sure that the simulated users are realistic, and refine them.
-
We will augment this with real data as we collect it, and we can use real data to help refine the synthetic data.
-
The amount of data to generate is the amount where we are confident we won’t see new failure modes.
Note: Replace or augment synthetic data with real data as systems are deployed. We can use real data as examples to get better synthetic data
4. Get the human expert to review the data
- pass/fail on specific criteria only
- reasoning for why it passes/fails. Here are examples of what we’re looking for
Most importantly, the critique should be detailed enough so that you can use it in a few-shot prompt for an LLM judge. In other words, it should be detailed enough that a new employee could understand it. Being too terse is a common mistake.
- Start with ~30 examples, go from there until you don’t see more failure modes
5. Implement a judge, and converge it to human-eval
NOTE: Human experts don’t always agree, maybe expect 85% convergence between humans and use this as the benchmark
- Do this low tech, just cycle through prompts manually and see how auto and human compare
- Include some few-shot examples
- Get both the LLM and Expert to provide explicit reasoning, forcing reconsideration of the eval
Align AI to human. Calibrate human to AI. Repeat.
The key insight is that aligning AI to human preferences is only half the battle. To build effective evals, we must also calibrate human criteria to AI output.
Many teams make the mistake of crafting elaborate eval criteria without first looking at the data. It’s like theorizing about user experience and defects from the ivory tower, without doing error analysis. From Who Validates the Validators: “It is impossible to completely determine evaluation criteria prior to human judging of LLM outputs.“
This leads to two types of bad criteria. First, irrelevant criteria that are a waste of time, such as generic metrics (e.g., helpfulness) or very low probability defects (e.g., grammar, spelling). Second, unrealistic, unattainable criteria that the technology isn’t ready for, such as autonomous agents back in 2023. Either way, teams squander effort that would have been better invested in evaluating actual defects that occur with moderate frequency.
NOTE: Human experts are not consistent. Even after they spend time aligning, they are not consistent. There are many things like context, fatigue, or personal biases to consider. Using one expert as ground truth may amplify noise. Strategies here include using multiple experts, or doing some test on human expert consistency.
6. Test the judge against the larger (synthetic/real) dataset, and do targeted improvements
- Fix agents with informed prioritization
- Because of the feature, scenario, persona categorization, we can identify specifically where the agents are failing
- We can also classify the types of errors and sort by that
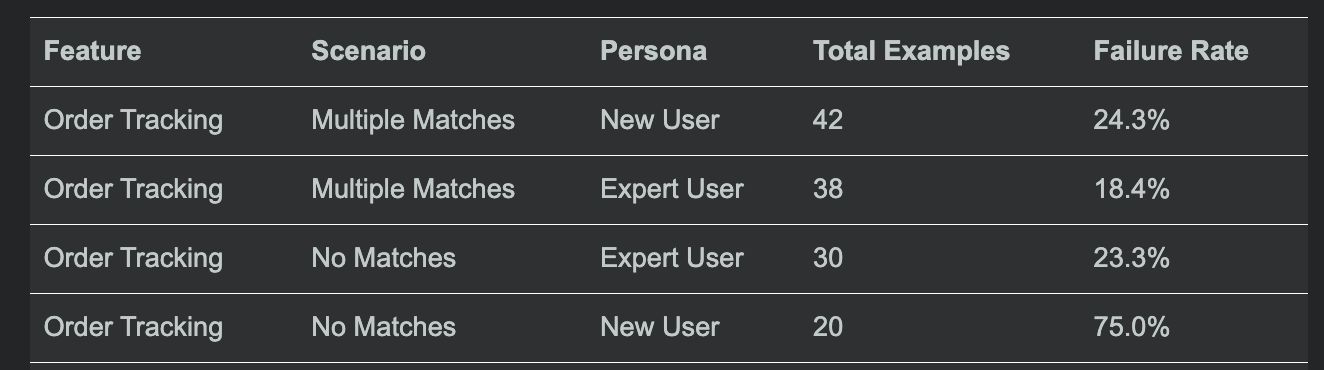
7. Deploy. More data. More judges
- Run evals on all real data that we collect
- Create more synthetic data if it seems necessary to find edge cases
- Create more judges as necessary for new evals
Here’s the flow diagram. Note that the numbers here don’t map exactly to what I have above.
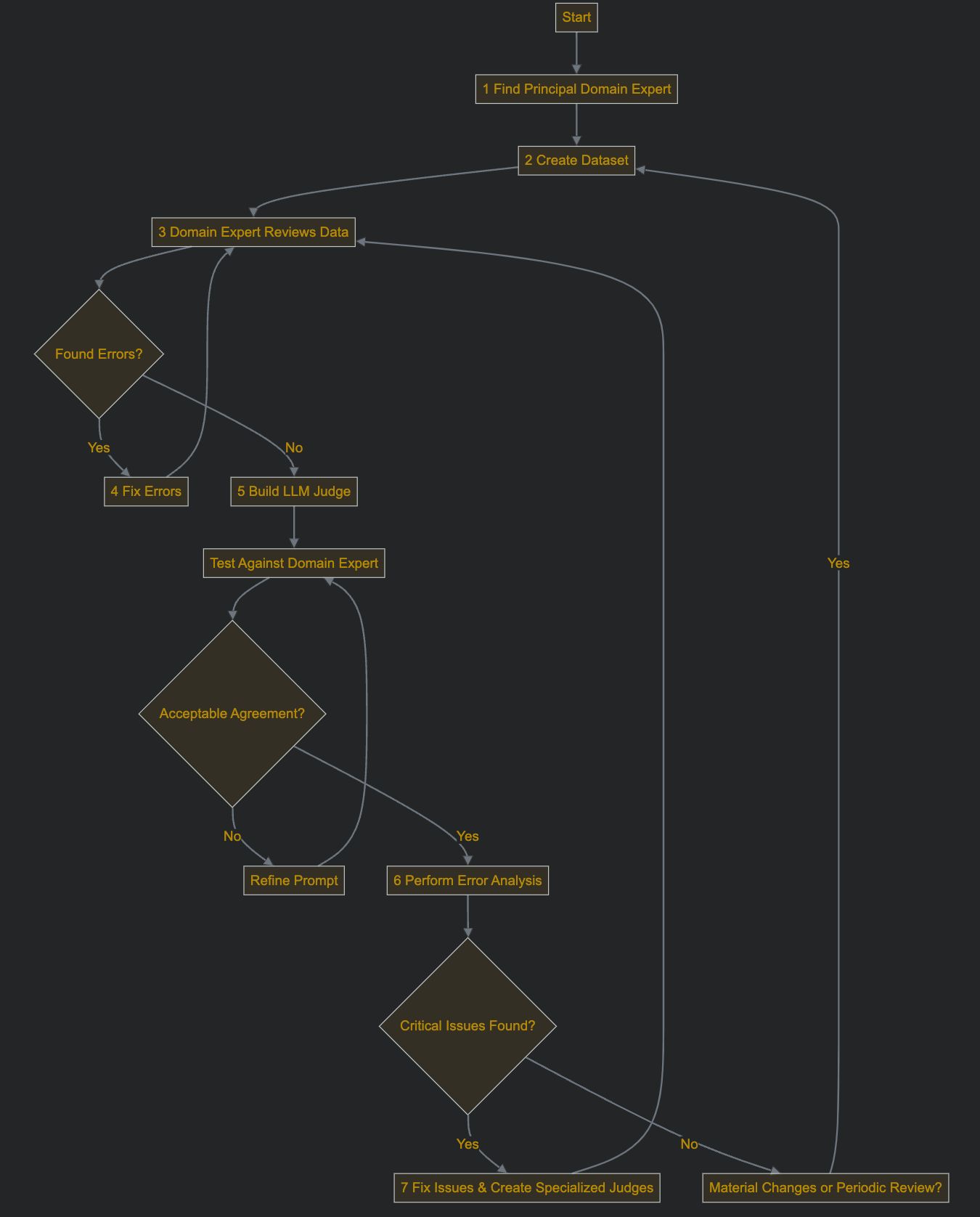
After you are done with this, promising directions
- Pairwise comparison judges to build out ELO scores for more subjective evals e.g. tone, conciseness, conversation-flow, etc.
- Finetuning - Fine-tuning is best for learning syntax, style, and rules, whereas techniques like RAG supply the model with context or up-to-date facts.
- Automated prompt improvement: e.g. https://aligneval.com/
- Continual in-context learning. Basically like RAG but injects relevant examples for few-shot learning into the prompt.
- Prompt-caching if we want a lot of examples
- Last response evaluation https://www.confident-ai.com/blog/llm-chatbot-evaluation-explained-top-chatbot-evaluation-metrics-and-testing-techniques
- G-Eval https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
Some Useful Readings
Creating a LLM-as-a-Judge That Drives Business Results
Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)